概念
一、集群
通常指的是由多个计算机或服务器组成的一个系统,这些计算机协同工作,共同完成某个任务
目标
提升系统的性能、可扩展性和容错能力
工作原理
将多个硬件资源连接在一起,形成一个统一的资源池,使得工作负载可以在多个机器之间分担,从而避免单个机器出现瓶颈。
常见类型
- 负载均衡集群:多个服务器分担同一应用的请求,减少某个服务器的压力。
- 高可用性集群(HA集群):多个节点同时运行,当一个节点发生故障时,其他节点可以接管任务,保证系统的持续可用。
- 计算集群:通过将多个计算节点连接在一起,用来处理复杂计算任务(如科学计算、大数据处理等)。
- 存储集群:多个存储设备联合成一个统一的存储池,提升存储的容量和访问速度。
好处
- 高可用性:容错能力强,某些节点故障时其他节点仍能提供服务。
- 可扩展性:可以通过增加节点来提高系统性能。
- 负载均衡:通过分摊请求,减轻单个节点的压力,提高响应速度。
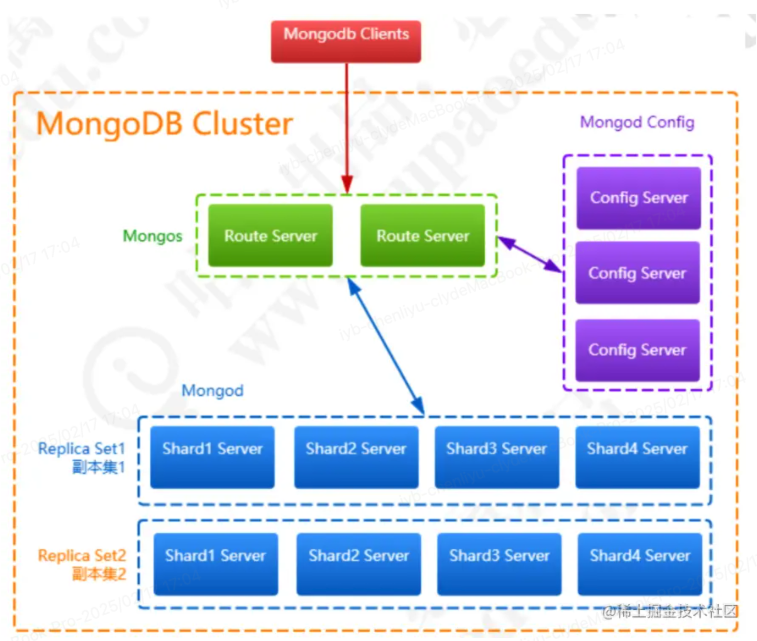
二、MongoDB里的集群
在 MongoDB 中,集群通常指的是将多个 MongoDB 实例(节点)组合在一起,以提高性能、可用性和扩展性
实例(节点)
在 MongoDB 中,实例(Instance) 或 节点(Node) 是指运行 MongoDB 服务的单个计算机或虚拟机,它可以是一个物理机或虚拟化的服务器
在 MongoDB 集群中,每个节点都是一个运行中的 MongoDB 数据库进程,可以有不同的角色和功能
节点类型
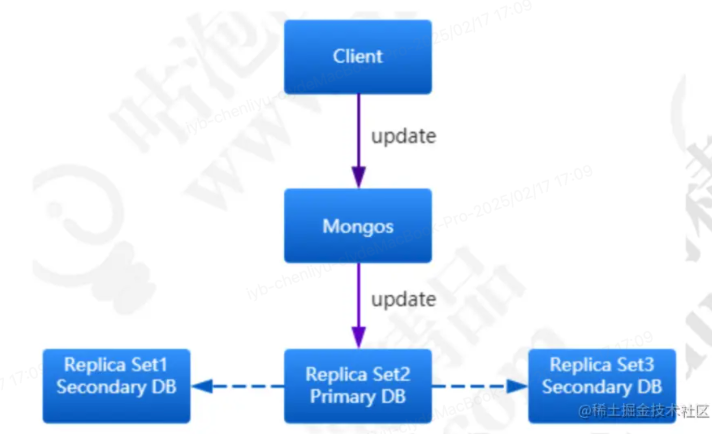
1. 主节点
- 作用:副本集中的主要节点,它负责处理所有的写操作。所有的写入请求都会发送到主节点
- 特点:同步数据到副本节点
2. 副本节点
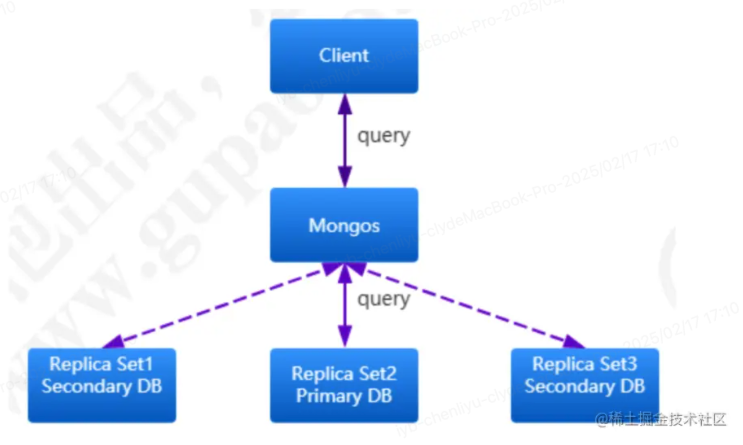
- 作用:副本集中的从节点,它通过复制主节点的数据来保持数据的副本。副本节点可以处理读操作,分担主节点的负载
- 特点:定期从主节点拉取数据并进行同步更新。副本节点也能提升为主节点,确保系统的高可用性。
3. 仲裁节点
- 作用:不会存储数据,它的唯一作用是参与副本集的选举过程。当主节点失效时,仲裁节点帮助选举出新的主节点
- 特点:不参与数据存储和复制,因此不占用存储空间,只用于协调和选举。
4. 分片节点
- 作用:在分片集群中,分片节点负责存储数据。MongoDB 将数据划分为多个分片,每个分片存储数据的一部分。分片节点可以存储大量的数据,并提供分布式存储和查询处理
- 特点:分片节点不必保存整个数据集,而是存储数据的子集(分片),它们是处理查询和存储数据的实际服务器。
5. 配置节点
- 作用:存储集群的元数据,管理分片集群的状态信息,包括每个分片存储的数据范围以及数据的分配情况。在分片集群中,配置节点为整个集群的路由决策提供支持
- 特点:分片集群的一部分,并且集群通常需要有三个配置节点来保证集群元数据的冗余备份和高可用性。
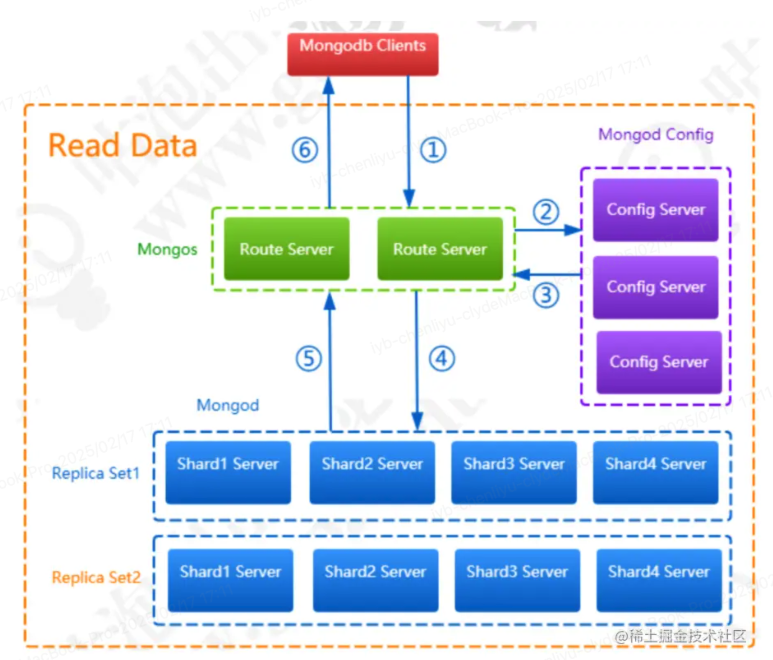
6. 路由节点(Mongos)
- 作用:Mongos 是 MongoDB 分片集群中的路由器,它充当客户端和集群中各个分片之间的中介。当客户端请求数据时,Mongos 会根据请求的分片键将请求路由到正确的分片节点。
- 特点:Mongos 不存储数据,也不参与数据的存储或复制,它只是起到请求转发的作用
集群类型
副本集
- 在副本集中的数据库,其所有的数据都会被 复制到副本集的每个节点上。
- 每个副本集节点(主节点和副本节点)都会持有数据库的完整副本,以确保数据的高可用性和容错能力。
- 主节点(Primary) 负责处理写入操作,而 副本节点(Secondary) 会实时复制主节点的数据,并保持一致性。
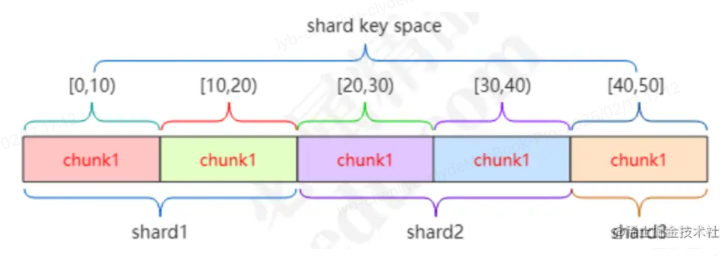
分片集群
- 在分片集群中,数据库的数据会根据分片键被分割成多个 数据块(chunks)。
- 这些数据块会被分配到不同的 分片节点(Shards)上,这样数据就被 水平分割,每个分片只存储一部分数据。
- 这种分布方式允许 MongoDB 横向扩展,处理更多的数据和更高的请求负载。
区别:
- 副本集关注的是数据冗余和高可用性,每个节点上都会有相同的数据副本;数据量不大
- 分片集群关注的是数据扩展性和负载均衡,数据被分割并分布到多个节点上,每个节点存储数据的一部分;数据量非常大
三、数据库
数据库是一个有组织的、结构化的数据集合,用于存储和管理数据。
数据库的作用
- 存储数据:数据库的主要作用是存储应用程序需要的数据,这些数据可以是结构化数据(例如表格数据)、半结构化数据(例如 JSON、XML 格式的数据)或非结构化数据(如图像、视频等)。
- 数据管理:数据库提供了强大的管理功能,包括数据的插入、更新、删除、查询、备份和恢复等操作。
- 数据一致性:数据库管理系统通过事务管理来确保数据的一致性,特别是在多个用户同时操作数据时,保证数据的完整性和一致性。
- 数据共享:数据库支持多个用户、多个应用程序同时访问同一数据,提供了并发控制、访问权限管理等机制。
数据库的组成
- 数据库表(Table):数据库的核心组成部分。表由行和列组成,行表示记录(也叫数据行),列表示字段(也叫属性)。每行记录表示一条数据,列则定义了数据的类型和内容。
- 字段(Field/Column):每个字段是表中数据的一个属性,通常每个字段都定义了数据类型(如整型、字符型、日期型等)。例如,一个“用户”表可能包含字段:用户ID、用户名、电子邮件、年龄等。
- 记录/行(Record/Row):记录是表中的一行,表示一个完整的数据实例。每个记录包含所有列的值。
- 索引(Index):索引是用来加速查询的工具,它在数据库的表上创建一个类似目录的结构,以便快速查找数据。
- 视图(View):视图是一个虚拟的表,它并不存储数据,而是从一个或多个表中动态生成数据。视图用于简化查询和数据的访问。
数据库类型
- 关系型数据库:使用表格结构来存储数据,并且遵循关系模型。数据表之间通过外键等方式进行关联。典型的关系型数据库有
MySQL、PostgreSQL、SQL Server和Oracle等。 - 非关系型数据库:不使用传统的表格结构,适合存储非结构化或半结构化的数据。包括文档数据库、键值存储、列族存储和图数据库等。常见的有
MongoDB、Cassandra、Redis等。 - 时序数据库:专门用于存储和管理时间序列数据(即按时间顺序排列的数据),如监控数据、传感器数据等。常见的有
InfluxDB和TimescaleDB等。 - 图数据库:用于存储图形结构数据,擅长处理复杂的关系型数据(如社交网络、推荐系统等)。常见的图数据库有 Neo4j 和 ArangoDB 等。
四、MongoDB与MySQL逻辑结构对比
| MongoDB | MySQL |
|---|---|
| 数据库 | 数据库 |
| 集合 | 表 |
| 文档 | 行 |